
티스토리 뷰
안녕하세요, 끙정입니다.
오늘은 집계함수를 알아보도록 하겠습니다.
함수는 입력값으로부터 모종의 계산을 하여 출력값을 리턴하는 장치입니다.
입력은 함수명 다음의 괄호 안에 인수로 전달하여 함수 호출문은 실행 결과를 리턴합니다.
SQL 함수의 입력값은 대부분 필드이며 계산식이나 * 같은 기호도 전달할 수 있습니다.
FUNCTION (필드)
1. COUNT
가장 대표적인 집계함수는 COUNT가 있습니다.
조건에 맞는 레코드 개수를 반환합니다.
SELECT COUNT(*) FROM tStaff;
/* 필드명을 지정해주면 보기 편하다. */
SELECT COUNT(*) AS "총 직원수" FROM tStaff;

WHERE 절을 포함해서 조건에 맞는 레코드 개수를 출력할 수도 있습니다.
/* salary 가 400이 넘는 직원의 수를 출력 */
SELECT COUNT(*) FROM tStaff WHERE salary >= 400;
/* salary 가 400이 넘는 직원의 이름을 출력 */
SELECT name FROM tStaff WHERE salary >= 400;
COUNT(*)는 지정한 필드값이 존재하는 레코드는 모두 셉니다.
따라서 아래와 같은 명령을 실행하면 동일한 결과가 나옵니다.
모두 필드값이 존재하기 때문입니다.
SELECT COUNT(name) FROM tStaff;
SELECT COUNT(depart) FROM tStaff;
값이 들어 있으면 무조건 수를 센다.
중복을 제거하고 개수를 반환시키고 싶다면, DISTINCT를 넣어주어야 합니다.
/* COUNT의 필드명을 입력할 때 DISTINCT를 넣어준다. */
SELECT COUNT(DISTINCT depart) FROM tStaff;
고유 개수만 집계한다.
COUNT 함수는 필드값이 들어있는 레코드를 세기 때문에, 필드값이 없는 즉, NULL 값인 레코드를 세지 않습니다.
유의할 점은 필드값을 넣지 않는 COUNT(*) 는 NULL이 있는 레코드도 숫자를 세니 주의하세요.
SELECT COUNT(score) FROM tStaff;
score 필드에는 NULL값이 2개 존재하기 때문에 18개만 반환합니다.
따라서 해당 필드에서 NULL 값이 존재하는 레코드 수를 반환하기 위해서는 아래와 같이 쿼리를 날립니다.
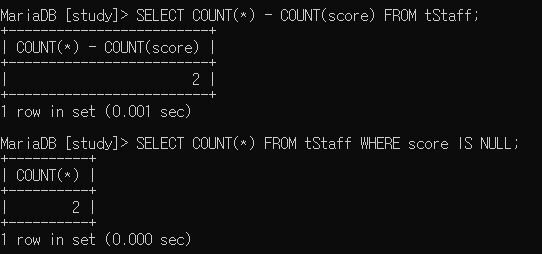
/* 전체 개수에서 NULL 값이 없는 개수를 빼주라. */
SELECT COUNT(*) - COUNT(score) FROM tStaff;
/* score가 NULL 인 레코드의 개수를 구해주라. */
SELECT COUNT(*) FROM tStaff WHERE score IS NULL;
2. 합계와 평균
통계값을 계산하는 집계 함수는 다른 곳에서도 일반적으로 많이 쓰이기에 익숙하실 겁니다.
DBMS별로 다소 차이는 있지만 대체로 유사합니다.
SQL Server만 표준편차와 분산을 구하는 함수가 조금 다를 뿐입니다.
| 설명 | Oracle | Maria DB | SQL Server |
| 총합 | SUM | SUM | SUM |
| 평균 | AVG | AVG | AVG |
| 최솟값 | MIN | MIN | MIN |
| 최댓값 | MAX | MAX | MAX |
| 표준편차 | STDDEV | STDDEV | STDEV |
| 분산 | VARIANCE | VARIANCE | VAR |
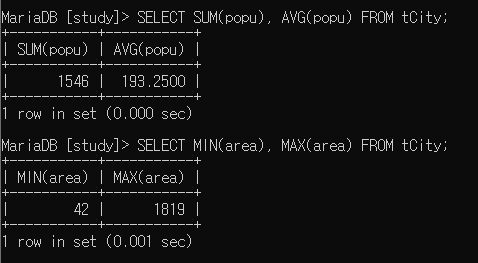
SELECT SUM(popu), AVG(popu) FROM tCity;
SELECT MIN(area), MAX(area) FROM tCity;
WHERE절을 붙이게 되면 조건에 해당되는 레코드의 집계만 뽑을 수 있습니다.
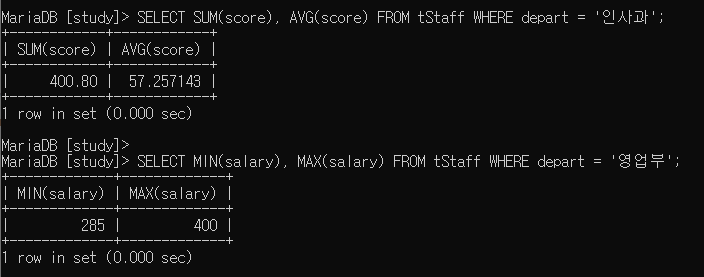
/* 인사과 직원들의 score에 대한 sum과 avg를 출력 */
SELECT SUM(score), AVG(score) FROM tStaff WHERE depart = '인사과';
/* 영업부 직원들의 salary에 대한 최솟값과 최댓값을 출력 */
SELECT MIN(salary), MAX(salary) FROM tStaff WHERE depart = '영업부';
다른 언어를 써보신 분도 아시겠지만, 집계함수는 수치값에만 사용할 수 있습니다.
문자열이나 날짜 형식의 필드에 집계함수를 적용하면 당연히 에러가 납니다.
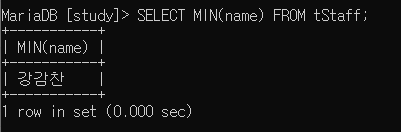
다만 MIN, MAX 함수는 사용이 가능한데요.
순서는 비교할 수 있기 때문입니다. MIN은 가장 앞선 레코드, MAX는 가장 뒤 레코드를 반환하게 됩니다.
SELECT MIN(name) FROM tStaff;
3. 집계 함수와 NULL
집계 함수와 함께 계산 할 때 주의할 점이 바로 NULL 값입니다.
위에서도 언급했지만, COUNT(*) 는 필드에 NULL이 있더라도 레코드는 존재하기에 집계를 합니다.
다만 COUNT(필드) 같은 경우는 NULL이 있다면 집계를 하지 않습니다.
그렇기에 집계에 오류가 생길 수 있습니다.
다음과 같은 사례를 지켜봅시다.
SELECT AVG(score) FROM tStaff;
SELECT SUM(score) / COUNT(*) FROM tStaff;
언뜻 보면 같은 결과를 내뿜을 것 같지만, 결과는 다릅니다.
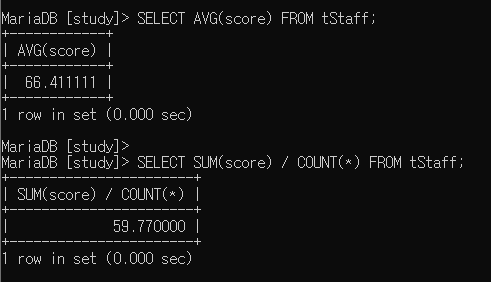
그 이유는 score 필드에 NULL 값이 2개 존재해서, AVG는 NULL 값을 제외하고 평균을 구하고,
SUM(score) / COUNT(*) 는 NULL 값을 제외하지 않고 평균을 구하기 때문입니다.
정확한 계산을 위해서는 다음과 같이 쿼리를 날려야 합니다.
SELECT AVG(score) FROM tStaff;
SELECT SUM(score) / COUNT(score) FROM tStaff;
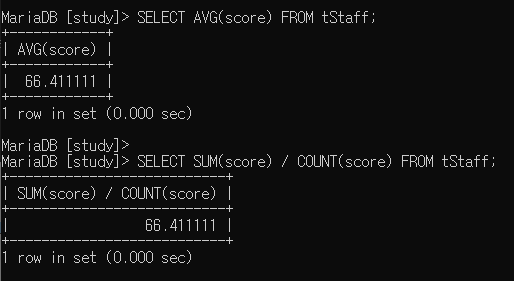
그러나 경우에 따라서 NULL 값을 집계에 포함해야 하는 경우도 있습니다.
그럴 때는 위와 같이 COUNT(*)로 계산을 해야 할 수도 있습니다.
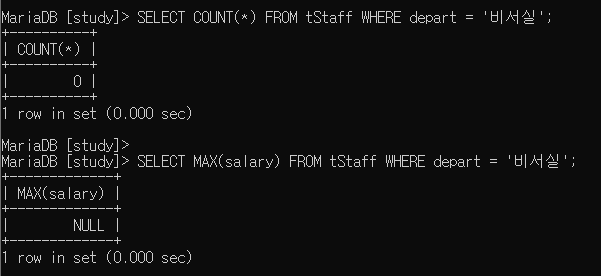
COUNT(*) 함수가 다른 집계 함수와 구별되는 차이점이 하나 더 있는데,
조건을 만족하는 레코드가 없더라도 하나도 없다는 뜻으로 0을 리턴한다는 것입니다.
반면에 다른 집계 함수는 0이 아닌 NULL 을 리턴합니다.
SELECT COUNT(*) FROM tStaff WHERE depart = '비서실';
SELECT MAX(salary) FROM tStaff WHERE depart = '비서실';
오늘은 그만 알아보겠습니다.
출처
http://www.yes24.com/Product/Goods/101637633
김상형의 SQL 정복 : 소문난 명강의 (무료특별판) - YES24
DBMS에 제약 없이 SQL을 활용한다!핵심 원리를 알려주는 SQL 바이블 DBMS 제품이나 개발툴이 아닌 SQL 언어 그 자체를 배우는 바이블 도서다. 특정 DBMS에 종속적인 사용법보다는 표준화된 데이터 관리
www.yes24.com
'SQL' 카테고리의 다른 글
| 삽입문에 대해서 알아보자 (feat. INSERT, INSERT SELECT, CREATE SELECT) (2) | 2023.01.29 |
|---|---|
| 그룹핑을 알아보자 (feat.GROUP BY, HAVING) (0) | 2023.01.29 |
| 효율적으로 출력하는 법을 알아보자 (feat. DISTINCT, ROWNUM, TOP, LIMIT, OFFSET FETCH) (2) | 2023.01.26 |
| ORDER BY 에 대해서 알아보자 (0) | 2023.01.26 |
| WHERE 절을 알아보자 2편 (feat. LIKE, BETWEEN, IN) (0) | 2023.01.26 |
- Total
- Today
- Yesterday
- aichip
- Apple
- perplexity
- Intel
- condenast
- 액침냉각
- sb1047
- Samsung
- Nvidia
- OpenAI
- datacenter
- Meta
- apple intelligence
- sql
- IDC
- genai
- alexa
- ai pc
- searchgpt
- ChatGPT
- SSI
- Amazon
- galaxyai
- aitv
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |