
티스토리 뷰
안녕하세요, 끙정입니다.
오늘은 서브 쿼리 탐구 2편, 서브쿼리 연산자에 대해서 알아보겠습니다.
전에 살펴본 IN 연산자와 비슷하게 ANY, ALL, EXISTS 가 있습니다.
천천히 살펴보겠습니다.
1. ANY, ALL
IN 연산자는 괄호 안의 결과 셋과 순차적으로 상등 비교하는데 비해,
ANY, ALL 연산자는 결과셋 전체와 비교합니다.
ANY는 그중 하나라도 만족하는 값이 있으면 참이고,
ALL은 모두 만족해야 참입니다.
ANY는 조건을 OR로 연결하는 것이고,
ALL은 조건을 AND로 연결합니다.
다음 두 쿼리를 통해 ANY와 ALL을 비교해보겠습니다.
/* 영업부서의 직원들의 어떤 salary 보다 큰 직원 */
SELECT name FROM tStaff WHERE salary > ANY
(SELECT salary FROM tStaff WHERE depart = '영업부');
/* 영업부서의 직원들의 모든 salary 보다 큰 직원 */
SELECT name FROM tStaff WHERE salary > ALL
(SELECT salary FROM tStaff WHERE depart = '영업부');

서브 쿼리로 따로 실행하면 영업부 직원의 월급은 285 ~ 400 범위에 있습니다.
ANY 연산자는 이 월급 중 어떤 값과 비교하더라도 월급이 더 많은 직원을 조사하므로,
최솟값인 285와 비교하는 것과 같습니다.
ALL 연산자는 영업부의 모든 직원보다 월급이 많은 직원을 조사하므로,
최댓값인 400과 비교합니다.
이는 다음 쿼리와 동일한 결과를 갖습니다.
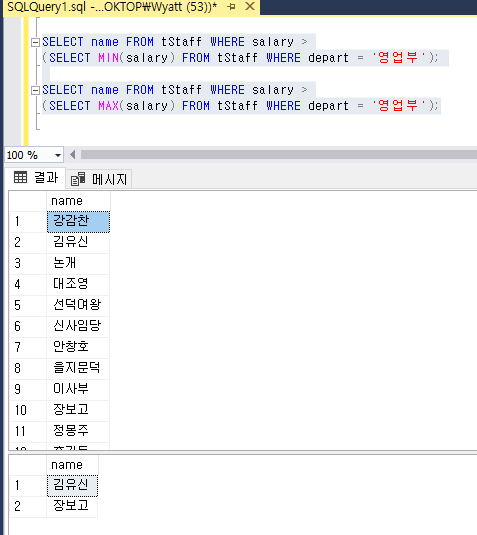
SELECT name FROM tStaff WHERE salary >
(SELECT MIN(salary) FROM tStaff WHERE depart = '영업부');
SELECT name FROM tStaff WHERE salary >
(SELECT MAX(salary) FROM tStaff WHERE depart = '영업부');
2. 연관 서브 쿼리 Correlated Subquery
지금까지 작성한 서브 쿼리는 단독으로 실행 가능하며 괄호 안쪽만 선택해서 실행해도 결과가 잘 나왔습니다.
이런 서브 쿼리를 독립 서브쿼리라 하며 외부쿼리에 값을 제공하는 역할을 합니다.
이에 비해 연관 서브쿼리 Correlated Subquery는 외부 쿼리의 필드 값을 참조하며 단독으로 실행하지 못합니다.
SELECT member, item, (SELECT price FROM tItem WHERE tItem.item = tOrder.item) price
FROM tOrder;
위 쿼리는 tOrder의 member와 item, 그리고 해당 item의 price까지 출력을 하는 쿼리입니다.
그러나 member와 item은 tOrder에 있고, price는 tItem에 있습니다.

따라서 서브 쿼리로 들어가 있는 price에 대한 SELECT문은 독립적으로 실행될 수 없습니다.
왜냐하면 아래 쿼리만으로는 tOrder 테이블을 참조할 수 없기 때문입니다.

위 서브 쿼리는 아래와 같이 메인 쿼리와 함께 있을 때,
메인 쿼리의 tOrder를 참조할 수 있습니다.
아래 쿼리는 따라서 에러가 나지 않고 잘 출력됩니다.
이러한 것을 연관 서브 쿼리라고 합니다.

그러나 보통은 어떤 필드를 어느 테이블에서 참조하는지 헷갈릴 수 있기 때문에,
테이블에 별명을 주고 별명으로 참조하는 것이 바람직합니다.
SELECT O.member, O.item, (SELECT price FROM tItem I WHERE I.item = O.item) price
FROM tOrder O;

하지만 JOIN을 사용하면 더 편한 쿼리를 쓸 수도 있습니다.
SELECT O.member, O.item, I.price FROM tOrder O, tItem I
WHERE O.item = i.item;
SELECT O.member, O.item, I.price FROM tOrder O JOIN tItem I
ON O.item = I.item;

3. EXISTS
EXISTS는 결과 셋이 있는지 없는지만 조사하는 단순한 연산자입니다.
뒤쪽 쿼리의 결과셋이 있으면 TRUE이고 그렇지 않으면 FALSE입니다.
단순하지만 직관적인 사용 예가 드물어 처음 보면 헷갈리는 연산자입니다.
다음 문장은 도시 목록에 면적이 1000이 넘는 도시가 있는지 조사하는 쿼리입니다.
SELECT name FROM tCity
WHERE EXISTS (SELECT * FROM tCity WHERE area > 1000);
위와 같이 WHERE 조건절이나 IF문과 함께 사용됩니다.

의미상 면적이 1000이 넘는 도시를 조사하는 것처럼 보이지만 그렇지 않습니다.
EXISTS 연산자의 서브 쿼리는 면적 1000 이상의 도시가 있는지만 따지기 때문에 항상 참이며,
따라서 모든 도시가 다 나타납니다.
그래서 EXISTS의 괄호 안에는 통상 연관 서브 쿼리가 옵니다.
위 쿼리를 제대로 작성하면 아래와 같습니다.
SELECT name FROM tCity C WHERE EXISTS (SELECT * FROM tCity WHERE C.area > 1000);

area가 1000이 넘는 춘천과 홍천을 제대로 출력했습니다.
그러나 이 쿼리도 효율적이지는 않습니다.
그냥 WHERE area > 1000 이 훨씬 간편합니다.
EXISTS 연산자가 제대로 기능을 발휘할 때는 외부 쿼리와 서브 쿼리의 테이블이 서로 다를 때입니다.
외부 쿼리의 필드 값으로부터 어떤 조건을 점검하고 그 결과 셋이 있는 경우만 추려낼 때 EXISTS를 사용합니다.
다음 쿼리는 한 번이라도 판매된 적이 있는 아이템을 출력합니다.
SELECT * FROM tItem I WHERE EXISTS /* EXISTS 로 존재여부에 대해 확인 */
(SELECT * FROM tOrder O WHERE O.item = I.item); /* 서브쿼리를 통해 tOrder의 레코드 반환 */

위 쿼리는 서브 쿼리를 통해 tOrder에 존재하는 레코드를 반환하고,
EXISTS를 통해 존재 여부를 확인하고 TRUE 값을 메인 쿼리를 통해 출력합니다.
반대 연산자는 NOT EXISTS입니다.
SELECT * FROM tItem I WHERE NOT EXISTS /* NOT EXISTS 로 존재여부에 대해 확인 */
(SELECT * FROM tOrder O WHERE O.item = I.item); /* 서브쿼리를 통해 tOrder의 레코드 반환 */

그런데 EXISTS 쿼리를 잘 살펴보면 굳이 EXISTS를 사용해야 되는가에 대한 의문이 들 수 있습니다.
저 쿼리는 사실 아래 쿼리와 같은 결과를 내기 때문입니다.

그냥 IN을 쓰면 되잖아요?!
EXISTS의 이점은 속도에 있습니다.
IN 연산자의 경우는 서브 쿼리의 결과 셋을 전부 구하고 비교를 시행하지만,
EXISTS는 단 하나라도 결과셋을 발견하면 즉시 리턴합니다.
필드 목록을 구하는 것도 아니고 개수를 세지도 않으며 오로지 존재 여부만 봅니다.
레코드가 수십만 개가 넘어가는 테이블 같은 경우는 EXISTS의 효율을 체감할 수 있습니다.
그만 알아보겠습니다.
출처
http://www.yes24.com/Product/Goods/101637633
김상형의 SQL 정복 : 소문난 명강의 (무료특별판) - YES24
DBMS에 제약 없이 SQL을 활용한다!핵심 원리를 알려주는 SQL 바이블 DBMS 제품이나 개발툴이 아닌 SQL 언어 그 자체를 배우는 바이블 도서다. 특정 DBMS에 종속적인 사용법보다는 표준화된 데이터 관리
www.yes24.com
'SQL' 카테고리의 다른 글
| 서브쿼리에 대해 알아보자 4편 (feat. UNION, UNION ALL, INTERSECT, MINUS, EXCEPT) (0) | 2023.02.06 |
|---|---|
| 서브쿼리에 대해 알아보자 3편 (feat. 인라인 뷰) (0) | 2023.02.06 |
| 서브쿼리에 대해 알아보자 1편 (feat.단일행, 다중열, 다중행 서브쿼리) (0) | 2023.02.05 |
| 시퀀스에 대해 알아보자 (feat. SEQUENCE, GENERATED AS IDENTITY, IDENTITY, AUTO_INCREMENT) (0) | 2023.02.05 |
| PRIMARY KEY에 대해 알아보자 (feat. CANDIDATE KEY, COMPOSITE KEY, UNIQUE) (0) | 2023.02.03 |
- Total
- Today
- Yesterday
- 액침냉각
- IDC
- perplexity
- datacenter
- ChatGPT
- aitv
- Samsung
- genai
- galaxyai
- condenast
- Apple
- OpenAI
- aichip
- sql
- Nvidia
- alexa
- Meta
- Amazon
- SSI
- ai pc
- apple intelligence
- Intel
- sb1047
- searchgpt
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |